n8n integration templates Use n8n's HTTP Request node to call Browserless REST endpoints and BrowserQL. Copy a template below, paste it into your workflow, and replace the token value with your API token.
Store your API token in n8n Credentials and reference it in the HTTP Request node as the token query parameter.
Quickstart: Take a screenshot
Sign in to your n8n instance and create a new workflow.
Add a manual trigger node to control when the workflow runs.
Add an HTTP Request node and configure it:
Method: POST
URL: https://production-sfo.browserless.io/screenshot?token=YOUR_TOKEN
Body: {"url": "https://example.com"}
Click "Execute workflow" to capture a screenshot. The response will contain the image buffer.
Copy the templates below to quickly add other Browserless endpoints to your workflows.
Templates
Screenshot
Capture a screenshot of any URL. POST https://production-sfo.browserless.io/screenshot with url in the body.
Use it to: visual monitoring, creating thumbnails, documenting web content.
Learn more about the Screenshot API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
0,
0
],
"id": "73479c89-44a3-4f49-ba59-97f99a23f5b9",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/screenshot",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "url",
"value": "https://www.example.com"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
240,
-80
],
"id": "afd7858f-1db8-4251-b3f9-aaa6a1f8ad95",
"name": "Screenshot buffer"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/screenshot",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "{\n \"url\": \"https://www.example.com\",\n \"options\": {\n \"encoding\": \"base64\"\n }\n}",
"options": {
"redirect": {
"redirect": {}
}
}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
240,
128
],
"id": "d2ba4e93-62ff-49ed-874a-78c077045b9d",
"name": "Screenshot base64"
},
{
"parameters": {
"content": "## Take a Screenshot\nYou can generate a screenshot as a **Buffer or Base64** Learn more about the [Screenshot API here.](https://docs.browserless.io/rest-apis/screenshot-api)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-368,
0
],
"typeVersion": 1,
"id": "82d552de-4927-4c8d-8ec1-8956d939d155",
"name": "Sticky Note"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "Screenshot buffer",
"type": "main",
"index": 0
},
{
"node": "Screenshot base64",
"type": "main",
"index": 0
}
]
]
},
"Screenshot buffer": {
"main": [
[]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy Screenshot Template to Clipboard PDF
Generate a PDF from a URL. POST https://production-sfo.browserless.io/pdf with url in the body.
Use it to: creating printable versions, archiving web pages, generating reports.
Learn more about the PDF API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-48
],
"id": "f7231783-1ab2-4587-bdaf-5139d2dfad95",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Generate a PDF\nYou can generate a PDF Learn more about the [PDF API here.](https://docs.browserless.io/rest-apis/pdf-api)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-48
],
"typeVersion": 1,
"id": "82cceda8-fee2-42f9-abef-a6178b8f9e69",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/pdf",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "url",
"value": "https://www.example.com"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
144,
-48
],
"id": "3373552b-36c4-4061-bd38-40398211904d",
"name": "PDF"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "PDF",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy PDF Template to Clipboard Content
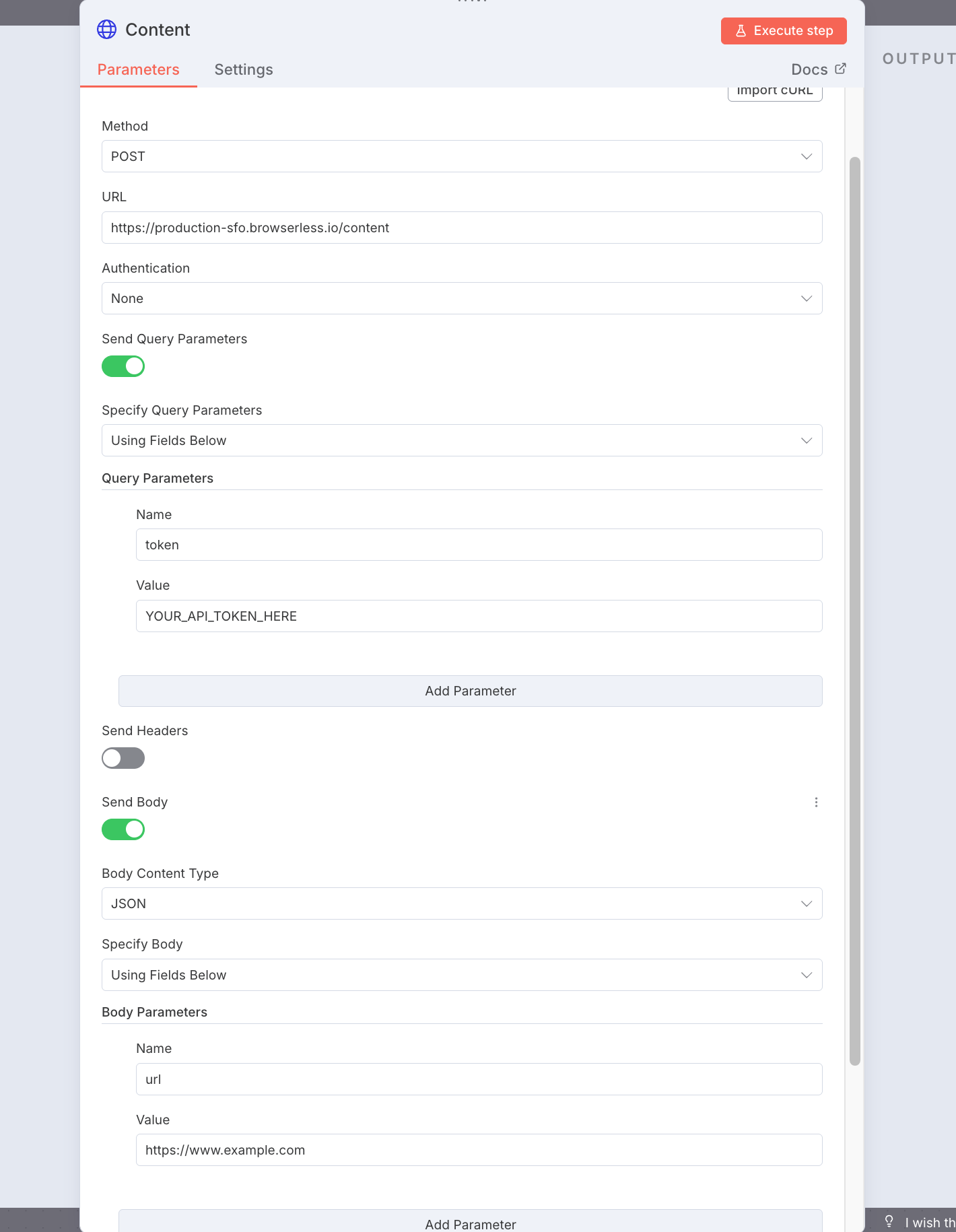
Fetch the page HTML. POST https://production-sfo.browserless.io/content with url in the body.
Use it to: web scraping, content analysis, data extraction.
Learn more about the Content API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
432,
-144
],
"id": "dc05fa4c-e60d-4082-8a1f-158e28032c38",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Scrape content\nFetch the HTML content of a site, read more about the [Content API here.](https://docs.browserless.io/rest-apis/content)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
64,
-144
],
"typeVersion": 1,
"id": "4f000aa2-aeb9-4bb9-83f6-5a5f9b0baec4",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/content",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "url",
"value": "https://www.example.com"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
640,
-144
],
"id": "a3aa914f-8f37-404d-b7c6-5f5c3493a303",
"name": "Content"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "Content",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy Content Template to Clipboard Unblock
Bypass bot detection and optionally return session details (cookies, browserWSEndpoint, content, screenshot). POST https://production-sfo.browserless.io/unblock with url and flags.
Use it to: accessing protected content, handling CAPTCHAs, managing cookies and sessions.
Learn more about the Unblock API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-48
],
"id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Unblock\nBypass common anti-bot measures, read more about the [Unblock API here.](https://docs.browserless.io/rest-apis/unblock)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-48
],
"typeVersion": 1,
"id": "b2c3d4e5-f6a7-8901-bcde-f12345678901",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/unblock",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "url",
"value": "https://www.example.com"
},
{
"name": "cookies",
"value": "true"
},
{
"name": "browserWSEndpoint",
"value": "true"
},
{
"name": "content",
"value": "true"
},
{
"name": "screenshot",
"value": "true"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
144,
-48
],
"id": "c3d4e5f6-a789-0123-cdef-123456789012",
"name": "Unblock"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "Unblock",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy Unblock Template to Clipboard Scrape
Extract structured data with CSS selectors. POST https://production-sfo.browserless.io/scrape with elements array.
Use it to: extracting specific content, structured data collection, automated data gathering.
Learn more about the Scrape API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-48
],
"id": "j7k8l9m0-n1o2-3456-jklm-no7890123456",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Scrape\nExtract structured data from web pages using CSS selectors, read more about the [Scrape API here.](https://docs.browserless.io/rest-apis/scrape)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-48
],
"typeVersion": 1,
"id": "k8l9m0n1-o2p3-4567-klmn-op8901234567",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/scrape",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"contentType": "raw",
"rawContentType": "application/json",
"body": "{\"url\": \"https://www.example.com\", \"elements\": [{\"selector\": \"h1\"}, {\"selector\": \"p\"}]}"
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
144,
-48
],
"id": "l9m0n1o2-p3q4-5678-lmno-pq9012345678",
"name": "Scrape"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "Scrape",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy Scrape Template to Clipboard Browser Query Language (BQL)
Run BrowserQL (GraphQL) to automate multi-step flows. POST https://production-sfo.browserless.io/chrome/bql with a GraphQL query.
Use it to: complex form filling, multi-step workflows, custom browser automation.
Learn more about BrowserQL .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-48
],
"id": "d1e2f3a4-b5c6-7890-defg-hi1234567890",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Browser Query Language (BQL)\nExecute complex browser automation using GraphQL, read more about [BQL here.](https://docs.browserless.io/browserql/start)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-48
],
"typeVersion": 1,
"id": "e2f3a4b5-c6d7-8901-efgh-ij2345678901",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/chrome/bql",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"contentType": "raw",
"rawContentType": "application/json",
"body": "{\"query\": \"mutation FormExample {\\n goto(url: \\\"https://www.browserless.io/practice-form\\\") {\\n status\\n }\\n select(selector:\\\"#Contact-Subject\\\",value:\\\"support\\\"){ time } \\n typeEmail: type(text: \\\"john@email.com\\\", selector: \\\"#Email\\\") {\\n time\\n }\\n typeMessage: type(\\n selector: \\\"#Message\\\"\\n text: \\\"Hello world!\\\"\\n ) {\\n time\\n }\\n solve(\\n type: cloudflare\\n ){\\n solved\\n }\\n waitForTimeout(time:3000){time}\\n screenshot{\\n base64\\n }\\n}\", \"variables\": {}, \"operationName\": \"FormExample\"}"
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
144,
-48
],
"id": "f3a4b5c6-d7e8-9012-fghi-jk3456789012",
"name": "BQL"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "BQL",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy BQL Template to Clipboard Function
Run custom JavaScript in a browser context. POST https://production-sfo.browserless.io/function with JS code.
Use it to: custom browser automation, complex data extraction, multi-step workflows.
Learn more about the Function API .
{
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-48
],
"id": "g4h5i6j7-k8l9-0123-ghij-kl4567890123",
"name": "When clicking 'Execute workflow'"
},
{
"parameters": {
"content": "## Function\nExecute custom JavaScript code in a browser context, read more about the [Function API here.](https://docs.browserless.io/rest-apis/function)",
"width": 304
},
"type": "n8n-nodes-base.stickyNote",
"position": [
-432,
-48
],
"typeVersion": 1,
"id": "h5i6j7k8-l9m0-1234-hijk-lm5678901234",
"name": "Sticky Note"
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/function",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"contentType": "raw",
"rawContentType": "application/javascript",
"body": "export default async function ({ page }) {await page.goto(\"https://example.com/\");\n const url = await page.content();\n const buffer = await page.pdf({ format: \"A4\" });\n const base64PDF = buffer.toString('base64');\n const screenshot = await page.screenshot({ encoding: \"base64\" });\n\n return {\n data: {\n url,\n screenshot,\n base64PDF\n },\n type: \"application/json\",\n };\n}"
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
144,
-48
],
"id": "i6j7k8l9-m0n1-2345-ijkl-mn6789012345",
"name": "Function"
}
],
"connections": {
"When clicking 'Execute workflow'": {
"main": [
[
{
"node": "Function",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "72f423f1e1c447db670aa3dc4919caee6676a7384f1dac4911c50b24b11b1249"
}
}
Copy Function Template to Clipboard Google Maps Scraper
Scrape Google Maps business listings (name, address, rating, reviews, phone, website) for a list of cities, paginate through results, and write everything to a Google Sheet. Uses stealth BQL to open Google Maps search results, click into each listing, and extract details before advancing to the next page.
Use it to: local lead generation, business directory building, competitor mapping across multiple cities.
Learn more about BrowserQL here .
{
"nodes": [
{
"parameters": {},
"id": "5e563e67-240b-4fc3-b92b-f393a3c34c03",
"name": "Start",
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-64,
-80
]
},
{
"parameters": {
"mode": "runOnceForEachItem",
"jsCode": "const cityName = $input.item.json.cities;\nconst maxPages = $input.item.json.maxPages || 6;\n\nif (!cityName) {\n throw new Error(\"cityName is required\");\n}\n\nconst searchQuery = `dentist near ${cityName}`;\n\nconst googleUrl = `https://www.google.com/search?q=${encodeURIComponent(searchQuery)}&sa=X&udm=1`;\n\nreturn {\n json: {\n cityName,\n searchQuery,\n maxPages,\n googleUrl\n }\n};"
},
"id": "dcf9844f-c921-4345-adae-301b1d5d1bd0",
"name": "Prepare Search",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
736,
-64
]
},
{
"parameters": {
"method": "POST",
"url": "https://production-sfo.browserless.io/stealth/bql",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "blockConsentModals",
"value": "true"
},
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ { \"query\": \"mutation GoToSite { viewport(width: 1366, height: 768) { width height time } goto(url: \\\"\" + $json.googleUrl + \"\\\", waitUntil: networkIdle) { status } reconnect(timeout: 30000) { browserQLEndpoint } }\", \"operationName\": \"GoToSite\" } }}",
"options": {}
},
"id": "dde09a44-ba04-43ed-b735-8e57b0475bda",
"name": "Open Google",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.3,
"position": [
960,
-64
]
},
{
"parameters": {
"jsCode": "const cityName = $(\"Prepare Search\").first().json.cityName;\nconst searchQuery = $(\"Prepare Search\").first().json.searchQuery;\nconst currentPageData = $input.first().json.data.scrapeBusinesses.value;\n\nconst results = [];\n\ntry {\n const businesses = JSON.parse(currentPageData);\n businesses.forEach((business, businessIndex) => {\n results.push({\n cityName,\n searchQuery,\n page: $input.first().json.currentPage,\n index: businessIndex,\n title: business.title || \"\",\n address: business.address || \"\",\n rating: business.rating || \"\",\n reviews: business.reviews || \"\",\n phone: (business.phone || \"\").replace(/^\\+/, \"\"),\n website: business.website || \"\",\n error: business.error || null\n });\n });\n} catch (e) {\n results.push({\n cityName,\n searchQuery,\n page: $input.first().json.currentPage,\n index: 0,\n title: \"\",\n address: \"\",\n rating: \"\",\n reviews: \"\",\n phone: \"\",\n error: `Parse error: ${e.message}`\n });\n}\n\nreturn results.map(item => ({ json: item }));"
},
"id": "d94b80e5-494d-43b2-9590-bc52cf97dc3b",
"name": "Parse Places",
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1328,
160
]
},
{
"parameters": {
"method": "POST",
"url": "={{ $json.browserQLEndpoint }}",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "token",
"value": "YOUR_API_TOKEN_HERE"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ { \"query\": \"mutation ScrapeTwentyPlacesThenClickNext {\\n scrapeBusinesses: evaluate(\\n timeout: 120000\\n content: \\\"\\\"\\\"\\n const sleep = (ms) =>\\n new Promise(resolve => setTimeout(resolve, ms));\\n\\n const clean = (value) =>\\n (value || \\\"\\\")\\n .replace(/[\\\\u200E\\\\u200F\\\\u2066-\\\\u2069]/g, \\\"\\\")\\n .replace(/\\\\s+/g, \\\" \\\")\\n .trim();\\n\\n const cardSelector =\\n '#rso [id^=\\\"pv-\\\"][role=\\\"button\\\"]:has([role=\\\"heading\\\"])';\\n\\n const waitForBusiness = async (expectedTitle, timeout = 10000) => {\\n const started = Date.now();\\n\\n while (Date.now() - started < timeout) {\\n const currentTitle = clean(\\n document.querySelector(\\n '#local-place-viewer h2.BK5CCe'\\n )?.textContent\\n );\\n\\n if (currentTitle === expectedTitle) {\\n return true;\\n }\\n\\n await sleep(200);\\n }\\n\\n return false;\\n };\\n\\n const waitForWebsite = async (panel, timeout = 2500) => {\\n const started = Date.now();\\n\\n while (Date.now() - started < timeout) {\\n const websiteLink = [\\n ...panel.querySelectorAll(\\\"a[href]\\\")\\n ].find(element => {\\n const text = clean(element.textContent);\\n const ariaLabel = clean(\\n element.getAttribute(\\\"aria-label\\\")\\n );\\n\\n return (\\n text === \\\"Website\\\" ||\\n /^Website:/i.test(ariaLabel) ||\\n element.getAttribute(\\\"data-item-id\\\") === \\\"authority\\\"\\n );\\n });\\n\\n if (websiteLink?.href) {\\n return websiteLink.href;\\n }\\n\\n await sleep(200);\\n }\\n\\n return null;\\n };\\n\\n const results = [];\\n\\n for (let index = 0; index < 20; index++) {\\n // Re-query every time because Google can rerender the cards.\\n const businesses = [\\n ...document.querySelectorAll(cardSelector)\\n ];\\n\\n const business = businesses[index];\\n\\n if (!business) {\\n break;\\n }\\n\\n const expectedTitle = clean(\\n business.querySelector('[role=\\\"heading\\\"]')\\n ?.textContent\\n );\\n\\n try {\\n business.scrollIntoView({\\n block: \\\"center\\\",\\n inline: \\\"nearest\\\"\\n });\\n\\n business.click();\\n\\n const loaded = await waitForBusiness(expectedTitle);\\n\\n if (!loaded) {\\n throw new Error(\\n `Timed out waiting for ${expectedTitle}`\\n );\\n }\\n\\n // Let the detail panel finish rendering.\\n await sleep(500);\\n\\n const panel = document.querySelector(\\n \\\"#local-place-viewer\\\"\\n );\\n\\n if (!panel) {\\n throw new Error(\\n \\\"Business detail panel not found\\\"\\n );\\n }\\n\\n const reviewBlock = [\\n ...panel.querySelectorAll(\\\".C9waJd\\\")\\n ].find(element =>\\n element.querySelector(\\\".Bye9Fc\\\") &&\\n /reviews?/i.test(clean(element.textContent))\\n );\\n\\n const rating =\\n clean(\\n reviewBlock\\n ?.querySelector(\\\".Bye9Fc\\\")\\n ?.childNodes?.[0]\\n ?.textContent\\n ) ||\\n clean(\\n panel.querySelector(\\\".rGaJuf\\\")\\n ?.textContent\\n ) ||\\n null;\\n\\n const reviews = [\\n ...(reviewBlock?.querySelectorAll(\\\"span\\\") || [])\\n ]\\n .map(element => clean(element.textContent))\\n .find(text => /reviews?/i.test(text)) ||\\n null;\\n\\n const phoneLinks = panel.querySelectorAll(\\n \\\"a[data-phone-number]\\\"\\n );\\n\\n const phoneLink =\\n phoneLinks[1] || phoneLinks[0] || null;\\n\\n const website = await waitForWebsite(panel);\\n\\n results.push({\\n index,\\n\\n title:\\n clean(\\n panel.querySelector(\\\"h2.BK5CCe\\\")\\n ?.textContent\\n ) || expectedTitle,\\n\\n address:\\n clean(\\n panel.querySelector(\\n \\\".C9waJd.y7xX3d span\\\"\\n )?.textContent\\n ) ||\\n clean(\\n panel.querySelector(\\n \\\".C9waJd.y7xX3d\\\"\\n )?.textContent\\n ) ||\\n null,\\n\\n rating,\\n\\n reviews,\\n\\n phone:\\n clean(\\n phoneLink\\n ?.querySelector(\\\".C9waJd\\\")\\n ?.textContent\\n ) ||\\n clean(\\n phoneLink\\n ?.getAttribute(\\\"aria-label\\\")\\n ?.replace(/^Call\\\\s+/i, \\\"\\\")\\n ) ||\\n phoneLink?.getAttribute(\\\"data-phone-number\\\") ||\\n null,\\n\\n website\\n });\\n } catch (error) {\\n results.push({\\n index,\\n title: expectedTitle,\\n address: null,\\n rating: null,\\n reviews: null,\\n phone: null,\\n website: null,\\n error: error?.message || String(error)\\n });\\n }\\n }\\n\\n return JSON.stringify(results);\\n \\\"\\\"\\\"\\n ) {\\n value\\n }\\n\\n nextPage: click(\\n selector: \\\"[aria-label='Next']\\\"\\n visible: true\\n timeout: 10000\\n ) {\\n time\\n }\\n\\n reconnect(timeout: 30000) {\\n browserQLEndpoint\\n }\\n}\", \"operationName\": \"ScrapeTwentyPlacesThenClickNext\" } }}",
"options": {
"timeout": 240000
}
},
"id": "8e334cf3-29c0-4e4c-b500-7e1b99ef393b",
"name": "Scrape Current Page",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.3,
"position": [
944,
160
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "currentPageData",
"name": "currentPageData",
"value": "={{ $json.data.scrapeBusinesses.value }}",
"type": "string"
},
{
"id": "browserQLEndpoint",
"name": "browserQLEndpoint",
"value": "={{ $json.data.reconnect.browserQLEndpoint }}",
"type": "string"
},
{
"id": "currentPage",
"name": "currentPage",
"value": "={{ $('Current Page').first().json.currentPage }}",
"type": "number"
}
]
},
"includeOtherFields": true,
"options": {}
},
"id": "ec284a3b-b02c-40a4-9d61-fe0b8fa0f9c5",
"name": "Save Page Data",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
1152,
160
]
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "page-check",
"leftValue": "={{ $('Save Page Data').item.json.currentPage + 1}}",
"rightValue": "={{ $('Prepare Search').item.json.maxPages }}",
"operator": {
"type": "number",
"operation": "lt"
}
}
],
"combinator": "and"
},
"options": {}
},
"id": "31b8902a-eefd-4f9f-b8ab-f75ce19c2660",
"name": "Check More Pages",
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
1728,
304
]
},
{
"parameters": {
"documentId": {
"__rl": true,
"value": "1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE",
"mode": "list",
"cachedResultName": "Cities",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": 731100957,
"mode": "list",
"cachedResultName": "MyCities",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/edit#gid=731100957"
},
"options": {}
},
"id": "d3a2e3f6-536b-418a-850b-e7482ea3addb",
"name": "Read Cities",
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
160,
-80
],
"credentials": {
"googleSheetsOAuth2Api": {
"id": "ZihTkNXDWsDwYrGv",
"name": "Google Sheets OAuth2 API"
}
}
},
{
"parameters": {
"options": {}
},
"id": "1ed2f0e0-2c09-428f-8c94-f4502ba02ede",
"name": "Loop Cities",
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
400,
-80
]
},
{
"parameters": {
"operation": "append",
"documentId": {
"__rl": true,
"value": "1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE",
"mode": "list",
"cachedResultName": "Cities",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/edit?usp=drivesdk"
},
"sheetName": {
"__rl": true,
"value": 1622505339,
"mode": "list",
"cachedResultName": "Results",
"cachedResultUrl": "https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/edit#gid=1622505339"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"Title": "={{ $json.title }}",
"City": "={{ $json.cityName }}",
"Page": "={{ $json.page }}",
"Address": "={{ $json.address }}",
"Rating": "={{ $json.rating }}",
"Reviews": "={{ $json.reviews }}",
"Phone": "={{ $json.phone }}",
"Website": "={{ $json.website }}"
},
"matchingColumns": [],
"schema": [
{
"id": "Title",
"displayName": "Title",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "City",
"displayName": "City",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Page",
"displayName": "Page",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Address",
"displayName": "Address",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Rating",
"displayName": "Rating",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Phone",
"displayName": "Phone",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Reviews",
"displayName": "Reviews",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
},
{
"id": "Website",
"displayName": "Website",
"required": false,
"defaultMatch": false,
"display": true,
"type": "string",
"canBeUsedToMatch": true
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"id": "7b603c79-3183-4044-b1c4-60adaf004f73",
"name": "Append to Sheet",
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 4.7,
"position": [
1504,
160
],
"credentials": {
"googleSheetsOAuth2Api": {
"id": "ZihTkNXDWsDwYrGv",
"name": "Google Sheets OAuth2 API"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "72bab080-7316-4c50-b778-fcf5320c9d48",
"name": "currentPage",
"value": "={{ $('Current Page').first().json.currentPage + 1 }}",
"type": "number"
},
{
"id": "4aa26113-9d13-43d1-9db4-bd3c8c33e7e8",
"name": "browserQLEndpoint",
"value": "={{ $('Scrape Current Page').first().json.data.reconnect.browserQLEndpoint }}",
"type": "string"
},
{
"id": "bfcb49ed-4548-4a01-b712-a71576218529",
"name": "maxPages",
"value": "={{ $('Prepare Search').first().json.maxPages }}",
"type": "number"
}
]
},
"includeOtherFields": true,
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
512,
288
],
"id": "55e778f0-d9b5-4d5a-a75f-754d26e2354d",
"name": "Pagination Loop",
"executeOnce": true
},
{
"parameters": {
"jsCode": "return [$input.first()];"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
1840,
544
],
"id": "b0164653-255a-45af-a9f2-25a7e95a9737",
"name": "Iterate next City"
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "browserQLEndpoint",
"name": "browserQLEndpoint",
"value": "={{ $json.data.reconnect.browserQLEndpoint }}",
"type": "string"
},
{
"id": "currentPage",
"name": "currentPage",
"value": 0,
"type": "number"
}
]
},
"includeOtherFields": true,
"options": {}
},
"id": "e4d21ed1-7517-430a-9358-5738ba1a9883",
"name": "Initiate Pagination",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
1184,
-64
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "6713fa86-0f8d-43c2-8416-07be75624501",
"name": "currentPage",
"value": "={{ $json.currentPage }}",
"type": "number"
}
]
},
"includeOtherFields": true,
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
736,
160
],
"id": "bd5cea47-2df8-40b5-a622-f5a39fa3cf9d",
"name": "Current Page"
},
{
"parameters": {
"content": "## Connect your Sheet\n**Link** it to a sheet identical to [this one](https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/)"
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
96,
-256
],
"id": "14540ab5-a9a4-4980-b64f-64b6f07b3f1b",
"name": "Sticky Note"
},
{
"parameters": {
"content": "## Add your API token here\n**Signup** for a [free account](https://www.browserless.io/signup/email?plan=free) if you don't have one.",
"height": 192,
"width": 176
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
912,
-272
],
"id": "b42d20a8-38c3-4df0-9f94-7cec9c4361fe",
"name": "Sticky Note1"
},
{
"parameters": {
"content": "## Add your API token here\n**Signup** for a [free account](https://www.browserless.io/signup/email?plan=free) if you don't have one."
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
880,
304
],
"id": "f0343bb2-5261-472b-bf9c-52e17403866c",
"name": "Sticky Note2"
},
{
"parameters": {
"content": "## Modify the search here\n**Change the search** query and maxPages per run here."
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
624,
-240
],
"id": "313db649-9116-47f3-9101-787244ae16cc",
"name": "Sticky Note4"
},
{
"parameters": {
"content": "## Connect your Sheet\n**Link** it to a sheet identical to [this one](https://docs.google.com/spreadsheets/d/1_3SDWehtZum1Lby8vKNILCf01zullfxYZkiUBONFldE/)"
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
1440,
-16
],
"id": "cc74ec7d-8d30-40ec-adba-29dca6cd7432",
"name": "Sticky Note5"
}
],
"connections": {
"Start": {
"main": [
[
{
"node": "Read Cities",
"type": "main",
"index": 0
}
]
]
},
"Prepare Search": {
"main": [
[
{
"node": "Open Google",
"type": "main",
"index": 0
}
]
]
},
"Open Google": {
"main": [
[
{
"node": "Initiate Pagination",
"type": "main",
"index": 0
}
]
]
},
"Parse Places": {
"main": [
[
{
"node": "Append to Sheet",
"type": "main",
"index": 0
}
]
]
},
"Scrape Current Page": {
"main": [
[
{
"node": "Save Page Data",
"type": "main",
"index": 0
}
]
]
},
"Save Page Data": {
"main": [
[
{
"node": "Parse Places",
"type": "main",
"index": 0
}
]
]
},
"Check More Pages": {
"main": [
[
{
"node": "Pagination Loop",
"type": "main",
"index": 0
}
],
[
{
"node": "Iterate next City",
"type": "main",
"index": 0
}
]
]
},
"Read Cities": {
"main": [
[
{
"node": "Loop Cities",
"type": "main",
"index": 0
}
]
]
},
"Loop Cities": {
"main": [
[],
[
{
"node": "Prepare Search",
"type": "main",
"index": 0
}
]
]
},
"Append to Sheet": {
"main": [
[
{
"node": "Check More Pages",
"type": "main",
"index": 0
}
]
]
},
"Pagination Loop": {
"main": [
[
{
"node": "Current Page",
"type": "main",
"index": 0
}
]
]
},
"Iterate next City": {
"main": [
[
{
"node": "Loop Cities",
"type": "main",
"index": 0
}
]
]
},
"Initiate Pagination": {
"main": [
[
{
"node": "Current Page",
"type": "main",
"index": 0
}
]
]
},
"Current Page": {
"main": [
[
{
"node": "Scrape Current Page",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"instanceId": "315bbb31459edf8c9d611746bcf962272828eacc9e3cd0dd4c853454e3e02d15"
}
}
Copy Google Maps Scraper Template to Clipboard Best practices for n8n
Binary vs base64 : For screenshots and PDFs, enable the "Download" option in n8n to handle binary responses, or request encoding: "base64" in the body to receive JSON responses.
Timeouts and retries : Long-running pages may exceed default timeouts. Configure timeout settings in your HTTP Request node and add retry logic for reliability.
Security : Store your API token in n8n Credentials or environment variables. Never hardcode tokens in plain text within your workflow templates.
Regional endpoints : Choose a regional endpoint close to your location for lower latency. Available regions include production-sfo (US West), production-lon (UK), and production-ams (Netherlands).
FAQ & Troubleshooting
The HTTP Request node returns 401 Unauthorized Check that the token query parameter is set on the request, not passed in the body or headers. If you're using n8n Credentials, confirm the credential is attached to the query parameter field, not a header.
The screenshot or PDF response looks corrupted n8n's HTTP Request node returns binary data by default. Either enable the "Download" option so n8n handles it as a binary file, or request encoding: "base64" in the body so Browserless returns JSON instead. See Best practices for n8n above.
The request times out on slow-loading pages Increase the timeout in the HTTP Request node's options, and add waitUntil or bestAttempt parameters to the Browserless endpoint to avoid waiting on pages that never fully settle.
Next steps