Calling the BrowserQL API
Once you have set up your query, you can export it to be called via an API.
- Click the Export as Code button.
- Choose your preferred language.
The export will include the endpoint, token, headers, and payload.
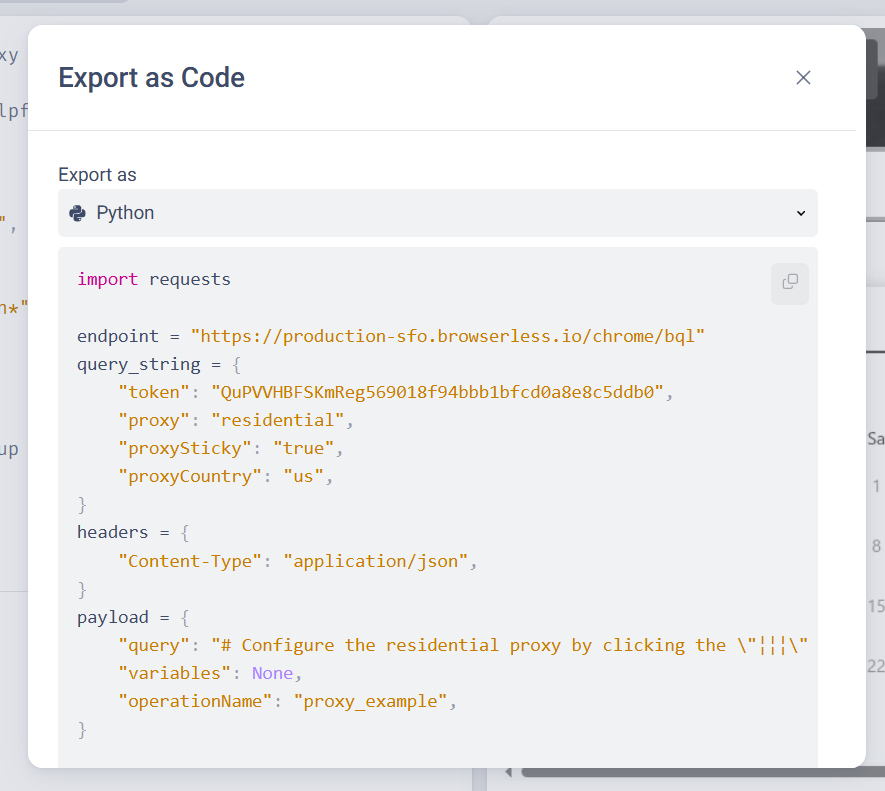
Of course, you might need multiple API calls for a scraping session, such as one to crawl the search results then a second to grab the details from each page.
- Javascript
- Python
- Java
const { JSDOM } = require("jsdom");
async function ExtractJobsHTML() {
const url = "https://production-sfo.browserless.io/chromium/bql?token=YOUR_API_TOKEN_HERE";
const options = {
method: 'POST',
body: '{"query":"mutation ExtractJobsHTML {\n goto(url: \"https://news.ycombinator.com\", waitUntil: firstMeaningfulPaint) {\n status\n }\n \n click(selector: \"span.pagetop > a[href=\'jobs\']\") {\n x\n y\n }\n \n html {\n html\n }\n}","variables":null,"operationName":"ExtractJobsHTML"}'
};
let response;
try {
response = await fetch(url, options);
} catch (error) {
console.error(error);
}
const json = await response.json();
const html = json.data.html.html;
const dom = new JSDOM(html);
const document = dom.window.document;
const rows = document.querySelectorAll("tr.athing");
const titlesAndLinks = [];
rows.forEach((row) => {
const anchor = row.querySelector("a");
if (anchor) {
titlesAndLinks.push({
title: anchor.textContent.trim(),
link: anchor.href.trim(),
});
}
});
console.log(titlesAndLinks);
}
ExtractJobsHTML();
import http.client
from bs4 import BeautifulSoup
import json
conn = http.client.HTTPSConnection("production-sfo.browserless.io")
payload = '{"query":"mutation ExtractJobsHTML {\\n goto(url: \\"https://news.ycombinator.com\\", waitUntil: firstMeaningfulPaint) {\\n status\\n }\\n \\n click(selector: \\"span.pagetop > a[href=\'jobs\']\\") {\\n x\\n y\\n }\\n \\n html {\\n html\\n }\\n}","variables":null,"operationName":"ExtractJobsHTML"}'
headers = {"Content-Type": "application/json"}
conn.request(
"POST",
"/chromium/bql?token=YOUR_API_TOKEN_HERE",
payload,
headers,
)
res = conn.getresponse()
response = res.read()
response_json = json.loads(response.decode("utf-8"))
html = response_json["data"]["html"]["html"]
soup = BeautifulSoup(html, "html.parser")
titles_and_links = []
for job in soup.find_all("tr", class_="athing"):
title_tag = job.find("a")
if title_tag:
titles_and_links.append(
{"title": title_tag.text.strip(), "link": title_tag["href"].strip()}
)
print(titles_and_links)
import com.mashape.unirest.http.HttpResponse;
import com.mashape.unirest.http.Unirest;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
public class ExtractJobsHTML {
public static void main(String[] args) throws Exception {
HttpResponse<String> response = Unirest.post("https://production-sfo.browserless.io/chromium/bql?token=YOUR_API_TOKEN_HERE")
.body("{\"query\":\"mutation ExtractJobsHTML {\\n goto(url: \\\"https://news.ycombinator.com\\\", waitUntil: firstMeaningfulPaint) {\\n status\\n }\\n \\n click(selector: \\\"span.pagetop > a[href='jobs']\\\") {\\n x\\n y\\n }\\n \\n html {\\n html\\n }\\n}\",\"variables\":null,\"operationName\":\"ExtractJobsHTML\"}")
.asString();
// Parse JSON response
JsonObject jsonResponse = JsonParser.parseString(response.getBody()).getAsJsonObject();
String html = jsonResponse.getAsJsonObject("data").getAsJsonObject("html").get("html").getAsString();
// Parse HTML with Jsoup
Document doc = Jsoup.parse(html);
Elements jobs = doc.select("tr.athing");
for (Element job : jobs) {
Element titleTag = job.selectFirst("a");
if (titleTag != null) {
System.out.println("Title: " + titleTag.text());
System.out.println("Link: " + titleTag.attr("href"));
}
}
}
}